Cómo nos ayuda la IA en Platanus

Los Large Language Models permiten resolver de manera sencilla y rápida varios problemas que se consideraban muy complejos. En Kalio, nuestro monolito en Rails, se nos presentaron varios de estos problemas y esta tecnología nos rescató. En ese proceso aprendimos varias cosas interesantes y acá te las contamos 🤓.
Te mostraré cuatro formas en las que usamos LLMs y después te daré un par de tips sobre desarrollo 🤖.
📚 Recomendar contenido de la librería
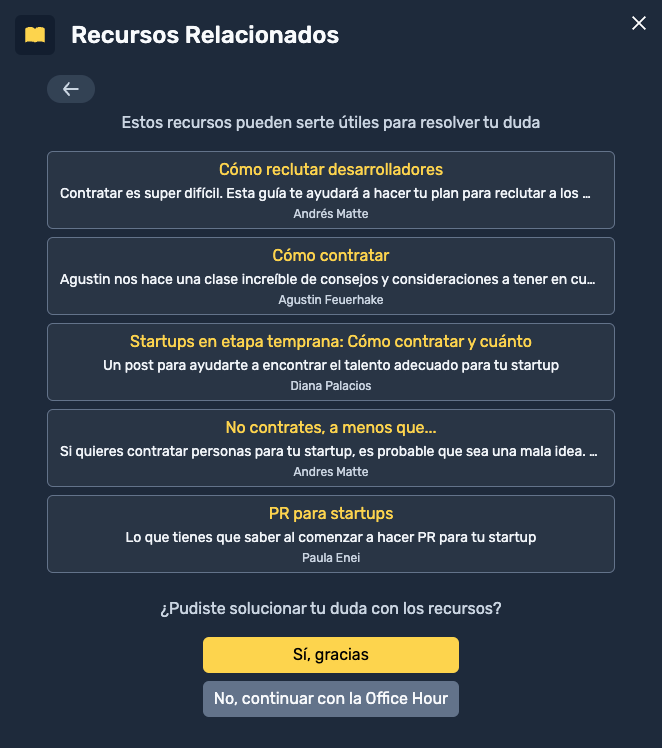
Uno de los fuertes más grandes de Platanus es la comunidad. De las primeras cosas que implementamos fue la posibilidad de pedirle una office hour o reunión corta a cualquier persona de la comunidad.
Con el tiempo se dio que se agendaban reuniones para hablar de temas bien conocidos, para los cuales tenemos algún blog post, video o libro que lo aborda de buena manera.
Para evitar estas office hours, decidimos pedir el asunto de la reunión y recomendar recursos de nuestra librería en base a él.
LLMs al rescate. La primera versión de la feature salió mas rápido de lo que esperábamos, en sólo una hora y media.
Con text-ada-002 de OpenAI, generamos embeddings de los recursos que tenemos en la librería. Básicamente vectorize(title + description + author + url). Guardamos el resultado en nuestra base de datos con pgvector. Al momento de recomendar, generamos un vector del asunto de la reunión y buscamos con distancia coseno los 5 recursos más cercanos usando Neighbor.
Una solución muy limpia y directa que funciona bien. La parte difícil la hace el modelo de embeddings 😌.
⚖️ Estandarizar entrada de texto
Cuando los fundadores postulan a Platanus, tienen que rellenar su “Perfil de Fundador”. Entre varias cosas, le pedimos información sobre los lugares donde han estudiado y trabajado.
Para hacernos una idea general de los fundadores que postulan, intentamos reconocer ciertas instituciones relevantes a las que han asistido, y ahí es donde aparecen los problemas.
Tec, ITESM, Tecnológico de Monterrey, son distintas formas de referirse a la misma universidad. Existen mil maneras de escribir los nombres de instituciones, entonces reconocerlas automáticamente no es trivial.
Se podría intentar limpiar los inputs y luego buscar un match en la base de datos, teniendo distantes variantes para cada opción, pero agregar cada variante de cientos de instituciones no es una tarea fácil.
Lo bueno es que ChatGPT ya ha visto todas esas variantes. Seguro le podemos pedir que transforme los nombres de instituciones a una forma estándar. Nuestro prompt se ve algo así.
Tu trabajo es estandarizar entradas de texto de nombres de instituciones.
Responde en JSON.
---
I: uch
A: { "institution" : "Universidad de Chile", "type": "university", "confidence" : 100 }
I: {{ entrada de usuario }}
A:
Hay más ejemplos y el contexto es más largo, pero se entiende la idea. Usamos varias técnicas de Learn Prompting. Lo más importante que aprendimos en el proceso era dar varios ejemplos. El darle contexto extra con los fields type y confidence también ayudó en ciertos casos borde.
Si te fijas bien, usamos “Responde en JSON”. Eso ya no es necesario actualmente usando Function Calling en las apis de OpenAI. Dejarlo explícito da la ventaja de que es compatible con otros modelos. En un futuro cercano, podría ser incluso un LLM self-hosteado.
Acá, que esperamos un JSON como respuesta, el modelo puede alucinar y dar respuestas incorrectas que no sean parseables. En ese caso, levantamos una excepción y dejamos que Sidekiq intente de nuevo.
Veamos algunos ejemplos de la transformación con ChatGPT:
| Input | Output |
|---|---|
| Univerisidad de los Andes | Universidad De Los Andes |
| ITESM Campus monterrey | Tecnológico De Monterrey |
| Berkeley | University Of California, Berkeley |
| Pontificia UC (Chile) | Pontificia Universidad Católica De Chile |
| Oracle Corporation | Oracle |
Las transformaciones que hace no son nada triviales. Incluso arregla las faltas de hortografía.
⛏️ Extracción de info
Las estructuras legales de las startups pueden ser complejas. Cliffs, vesting, stock options y más palabras en inglés pueden aparecerse. Todos esos detalles nos importan, por lo que al postular la entrada es de texto libre.
En el proceso de revisión, nos gustaría tener algunos números exactos, que seguro se pueden extraer de la descripción en palabras del Cap Table. La tecnología para resolver el problema será… 🥁🥁 LLMs. Inesperado.
Le damos un rol “Tu trabajo es…” como prompt y luego le agregamos toda la información relacionada al Cap Table.
Le pedimos una respuesta en JSON con el field ‘reasoning’ y otro field con el valor calculado. Con lo de reasoning buscamos un efecto similar al del famoso prompt “Take a deep breath and work on this problem step by step”.
En Kalio, a partir de una descripción simple del Cap Table y otra descripción de los fundadores que programan, podemos obtener el procentaje del fundador técnico así:
Context:
---
Tu trabajo es determinar el porcentaje de participación del
cofundador técnico. Usa sólo la información textual para responder.
Responde en JSON con el formato { "reasoning" : string, "percentage": integer }
Prompt:
---
Composición societaria:
X Capital -> 10%
Rodrigo Suárez -> 65%
Antonia Jiménez -> 25%
Fundadores que programan:
Antonia tiene 7 años de experiencia en desarollo web en Amazon. Experta en
arquitectura serverless. Rodrigo también sabe de programación, pero solo ha
tomado un par de cursos online.
Answer:
{ "reasoning": "Antonia es la fundadora técnica, ya que tiene más experiencia
en el desarrollo de software", "percentage": 25 }
🗜️ La clásica: resúmenes
Las postulaciones que recibimos tienen un montón de data. En nuestro panel de revisión, creamos una vista de resumen para tener un contexto rápido. Acá es donde los LLMs brillan ✨.
Pasamos ciertas secciones de la postulación a un prompt con la instrucción “crea un resumen en bullet points”. Cada sección la complementamos con la información básica de la postulación.
Tenemos cuidado de no pasarnos con el límite de tokens. En caso de que el texto a resumir sea demasiado largo, simplemente lo dividimos en secciones, resumimos cada sección y unimos el output de resúmenes.
A esta última limitación le queda poco tiempo de vida; cada vez va ser menos relevante con ventanas de contexto más grandes.
Hasta hace un un poco más de un año, no había una forma sencilla de generar y con buenos resultados resúmenes de texto. Punto para los LLMs.
👹 El diablo está en los detalles
En el proceso de desarrollar estas features, nos dimos cuenta que Integrar LLMs en una app no es complicado. Pero mantenerlo en el tiempo y mejorarlo para tener buenos resultados sí puede serlo. Dejo algunos hacks que nos han sido muy útiles.
- 🔁 Development Loop: El prompting sigue siendo relevante, aunque yo diría que no por mucho más. Hay que ir ajustando incrementalmente el prompt hasta llegar a un resultado decente. Armar un buen setup de desarrollo ayuda a no morir en el intento. Si esperas una respuesta exacta, como en la extracción de info, arma unos 10 test cases, lo más variados posibles (pero realistas) y haz las llamadas a la API en paralelo para que no pierdas el día completo. Si buscas sólo comparar respuestas, como en el caso de los resúmenes, aumenta el history buffer de tu consola e imprime los pares (prompt, respuesta) y empieza a iterar a mano.
- 📉 Ya no es 2021: Ya no le llueve plata a las startups. Hay que ahorrar. En ciertas situaciones, como para la estandarización de entradas de texto, se dará el caso que se llama a la API con exactamente el mismo prompt. Memoiza los pares (input, output) para no hacer llamadas repetidas a la API. Ahorrarás tiempo y plata 😉. A nosotros nos ayudó para reducir las llamadas en 29.3% 💸.
- 🔙 Máquina del tiempo: A medida que tus usuarios usen tu producto, se irán haciendo llamadas a la API de tu LLM. Guarda todos los inputs y outputs de la API en tu base de datos, idealmente con tags para poder diferenciar de donde vienen. Con esto vas a poder debuggear más tarde cualquier output inesperado y tener data realista para seguir mejorando tus prompts.
- 📀 Disco rayado: Los provedores de LLM se caen y tu app tiene que estar preparada. A eso súmale que a veces las alucinaciones te pueden dar resultados inesperados. Estos dos factores hacen necesario un mecanismo de retry. Hasta cinco retries con intervalos crecientes de espera entre ellos es un buen punto de partida. Evita los retries infinitos. Si hay un bug en tu código, se puede repetir la llamada a la API todo el tiempo y tu cuenta se va a a ver así: 📈.
En Platanus, los LLMs nos han agregado un valor gigante. De un día para otro teníamos a mano una herramienta que nos permitía solucionar problemas complejos y que nos abrió muchísimo el rango de funcionalidades que podemos desarrollar.
De hecho, ya hemos pensado en agregar RAG y herramientas externas usando con Langchain 🦜⛓️ y LlamaIndex 🦙, prompting mejorado con Autogen e integración con LLMs locales usando Ollama + LiteLLM.
Se siente como navidad 🎄.
Y eso es sólo con las primeras versiones de la tecnología. El espacio AI se está moviendo demasiado rápido y nos cuesta imaginar qué vamos a poder construir en un par de años ✨🤖.
